AI 正在吃掉软件,但吃的方式和大多数人想的不一样。
所有人都在唱衰 SaaS,但 SaaS 解决的真问题不会消失。 Coding Agent 可以在几天内复刻一个传统 SaaS 产品的核心功能,“传统 SaaS 可复制性快速提高”已经成了共识。但客户怎么管、合同怎么审、项目怎么推进、合规怎么跟踪,这些问题不会因为 Agent 的出现而消失。变的是解决方式和商业模式。
大多数公司只是用 AI 强化传统。 加了一个 AI 对话框,底层还是某类数据的增删改查。加了一个 AI 总结按钮,产品的主对象还是文档和看板。AI 成了功能层的增强,产品范式没有变。
Coding Agent 已经跑出了范式级产品,但垂直领域还没跟上。 Claude Code 在代码领域验证了 Agentic-first 的范式,用户给目标,Agent 自主规划和执行。但产品研究、合同管理、投资分析这些场景,还在靠 Claude、ChatGPT 这类对话工具,没有出现等价的垂直产品。
这三个现实叠在一起,指向一个判断:问题不在于 Agent 不够强,而在于垂直领域怎么做出真正的 Agentic-first 产品,而不只是给传统产品加 AI 功能。
在一段时间的探索和实践后,我认为 Agentic Asset Loop 是对这个问题的一种回答。
Agentic Asset Loop 是什么
Agentic-first 回答的是”软件如何从人操作功能,变成系统围绕目标持续运行”。Agentic Asset Loop 在此基础上追问:这些运行结束之后,什么会留下来,并让下一次运行变得更好?
大多数 AI 产品的循环停在”生成”这一步:用户提出问题,AI 完成任务,输出一份结果,结束。每次都是一次性消费,产出不会成为下一次的起点。Agent 只是运行机制,真正的产品是它持续生产和校验的那些业务资产。
Agentic Asset Loop 要形成的是一个增量循环:用户设定目标,Agent 执行任务,结果沉淀为结构化资产并绑定证据,人审核和校准关键判断,下一次任务在已有资产上做增量,输出从资产生成而不是每次重写。每一轮都叠在上一轮基础上,系统越用越厚。
真正的区别不在单次输出质量,这个迟早会被 LLM 拉平。区别在于一年之后,系统里积累了什么。
反过来说,它不是什么?
- 它不是 Chat。 Chat 的默认锚点是对话历史,不是业务资产。它可以接数据库和知识库,但如果产品主对象仍然是一次次问答,产出就很难自然进入资产循环。Asset Loop 要求产出沉淀为带证据链、有置信度、可增量更新的持久资产。
- 它不是 Agentic Feature。 在传统产品上叠加 AI 能力,产品的主对象还是数据的增删改查,AI 只是加速了某个环节。Asset Loop 要求产品的主对象和核心价值由 agent loop 定义,目标驱动、运行可追溯、资产持续积累,是全新的产品范式。
- 它不是通用 Agent。 通用 Agent 的价值锚点是任务完成。它可以做很多事,但除非外部产品层为它定义稳定的业务对象、资产结构和质量标准,结果通常停留在一次性交付。垂直 Agent 的价值在于它理解业务对象是什么、资产结构长什么样、质量标准由谁定义。
那这个循环怎么保障能真的转起来?靠 5 个设计原则。
5 个原则
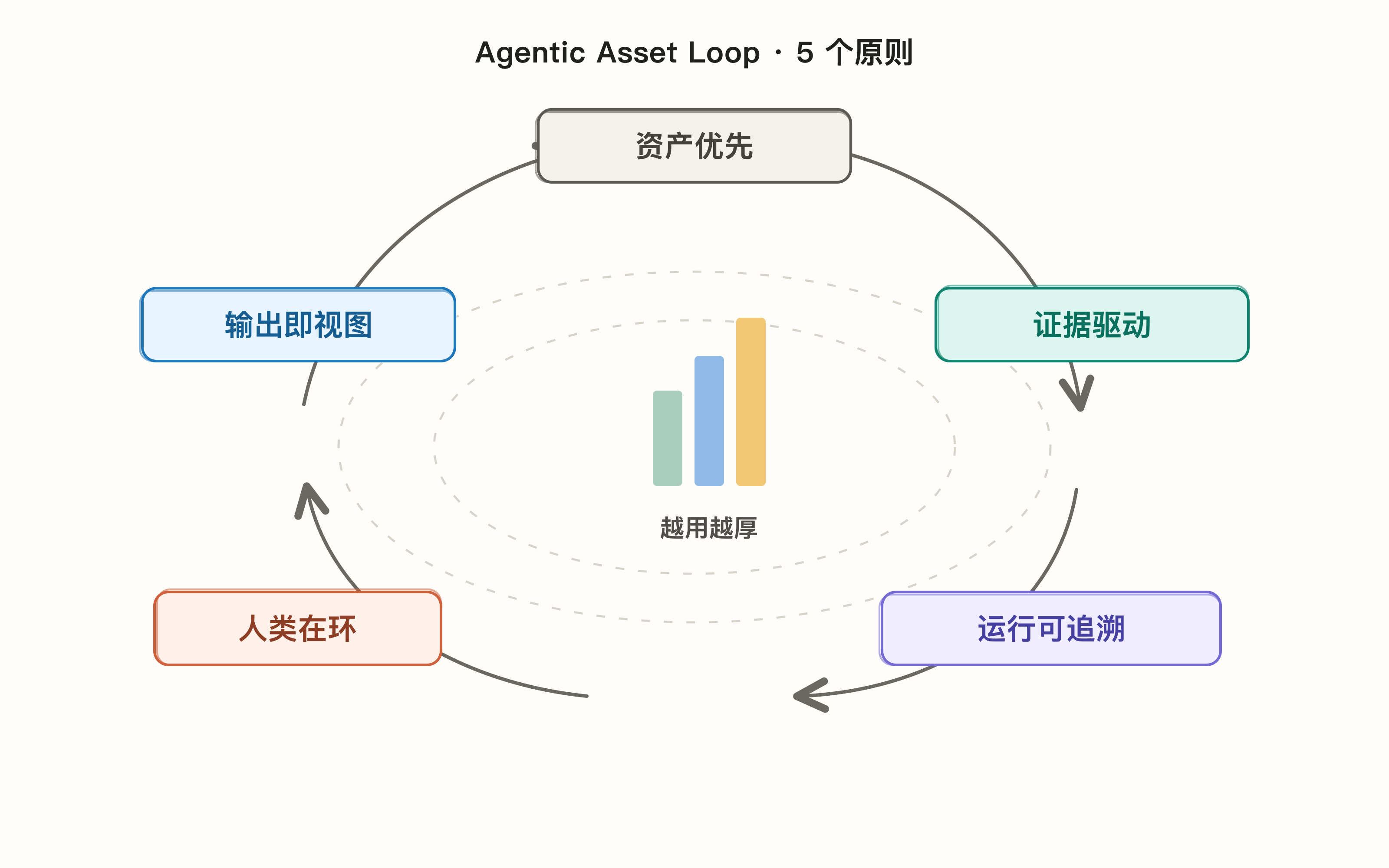
让 Agentic Asset Loop 转起来,靠的不是给 Agent 加更多工具,而是给循环中的每个节点加约束。
- 资产优先(Asset-first) 对应”沉淀”环节。重要结果必须沉淀成结构化的业务实体。
- 证据驱动(Evidence-backed) 对应”可信”环节。每个判断必须能回答:证据在哪、来源是什么、什么时候采集、置信度多少、谁确认过。
- 运行可追溯(Run-traceable) 保障”运行”环节。每次 Agent 执行都要有运行记录。
- 人在环路(Human-in-the-loop) 解决”校准”问题。人不只在最后验收,高影响动作必须经人确认,包括修改核心判断、删除旧结论、提高置信度、生成外部报告。
- 输出即视图(Output-as-view) 对应”输出”环节。报告、摘要、图表都是资产的视图,不是事实来源本身。
5 层架构
原则管的是循环怎么转,架构管的是产品由什么组成。每一层都是某个原则落地时需要的承载结构。
- 业务目标层 定义要做什么。用户想完成什么,不是”帮我搜一下 Notion”,而是”持续跟踪 Notion 的 AI 功能演进”。没有结构化的目标,Agent 只能接收一次性命令,无法围绕目标持续运行。
- 任务运行层 定义怎么执行。把 Agent 的执行变成可管理的业务任务,包括目标(Goal)、运行记录(Run)、计划(Plan)、状态(State)、过程追踪(Trace)、审核队列(Review Queue)、结果(Result)、记忆(Memory)、评估(Eval)。这一层承载”运行可追溯”原则,是区分”AI 工具”和”Agentic 系统”的分界线。
- 业务对象层 定义围绕什么工作。产品、客户、合同、候选人、项目、供应商,这些结构化的业务实体是 Agent 任务的锚点。没有业务对象,Agent 就只是在串工具,不是在推进业务。
- 结果资产层 定义什么被留下来。判断记录、证据链、知识页面、决策日志、版本历史。这一层承载”资产优先”和”证据驱动”原则,是 Agentic Asset Loop 最核心的一层。
- 治理层 定义如何确保质量。权限、审计、成本控制、质量评估、人工审核。承载”人类在环”原则,确保系统可控、出了问题能追溯、该问责时问得到人。
大多数现有产品只做了部分治理层。真正区分 Agentic-first 和 Agentic feature 的是中间三层:任务运行、业务对象、结果资产。这三层空着,产品就只是一个能干活的 Agent;这三层填满了,产品才是一个持续积累价值的系统。
这套架构适合结果会长期复用、判断需要证据、过程需要审计、信息持续变化的领域,比如产品研究、合同管理、投资分析、合规跟踪、CRM、用户研究。对于用完即走、低风险、强标准化的场景,比如文件转换、简单预约、高频交易,就有点过度设计了。
场景拆解
架构是通用的,落到每个领域时填入不同的业务对象和资产类型。拿两个场景来说明。
场景一:产品调研
传统做法是用 Agent 做一次分析,输出一份报告,存起来。下次再做,从零开始。
按 Agentic Asset Loop 的设计,产品调研工具应该围绕每个产品建立持久的知识空间。用户输入产品名和调研目标,Agent 发现信息源并抓取,提取产品判断并绑定证据和来源快照,写入产品知识空间,用户审核并校准置信度。之后可以手动或自动触发增量更新,Agent 只处理变化部分,每一轮产出叠在上一轮基础上。
对应到五层架构:业务目标是”持续跟踪某个产品的竞争动态”;任务运行层记录每次研究的完整过程,包括用了哪些来源、跳过了什么、花了多少 token;业务对象是”某个产品”;结果资产是带证据链和置信度的产品判断;治理层是置信度阈值和人工审核机制。三个月后回来看一个产品,判断链、变化时间线、功能地图全在那里,哪些是 Agent 生成的、哪些是人确认过的、哪些已经过期需要更新,一目了然。
场景二:合同管理
同样的逻辑换一个领域。传统合同管理系统的核心对象是”一份合同文件加一条记录”,Agent 能帮你搜条款、做摘要、标风险点,但审查完的判断留在了邮件或批注里,下一份类似合同来了不会自动复用。
如果按 Agentic Asset Loop 来做,数据粒度要深入到条款级别。业务对象变成”合同加条款加审查意见加风险标记”,每个审查意见绑定具体条款原文和公司政策依据,写入结构化的审查资产库。下一份类似合同进来时,系统自动调用已有的审查资产:上次同类型合同的赔偿上限条款你们调低了 30%,这次要不要沿用同样的谈判策略?Harvey 在做的就是类似的事,它的 Vault 和 Agent Builder 把法律资料、工作流和专家判断沉淀为可复用的法律工作资产。
两个场景的载体不同,产品调研积累的是产品判断和证据链,合同管理积累的是审查意见和条款级知识,但闭环逻辑相同。
横向对比
把市面上的产品按这套框架排一下,大致分三类。
第一类:工具就绪。 Cursor、NotebookLM、Manus 各代表一个方向。
Cursor 在代码领域验证了完整的 Agentic-first 范式,用户给目标,Agent 自主规划和执行。但它的成功有一个前提条件:代码领域天然有编译器和测试套件作为确定性反馈层,Agent 写错了测试会告诉你,这是其他领域不具备的先天优势。
NotebookLM 在研究领域做到了基于原始资料的引用和理解,但它的核心动作是”导入资料、理解、提问”,不是”初始化、增量更新、判断沉淀”,它帮用户理解一组资料,但不帮用户持续理解一个领域。
Manus 作为通用 Agent 走得更远,能自主规划、调用工具、异步执行、交付完整产出,但它的产出仍然是一次性的文件和报告,没有结构化的资产层来承接。
这三个产品各有所长,但它们的默认价值锚点都不在业务资产的积累上。Agentic Asset Loop 关注的是另一个问题:任务完成之后,什么会以业务资产的形式留下来。
第二类:平台就绪。 Dify、Coze 这类产品让用户用可视化方式搭建 AI 工作流,降低了 Agent 能力的组装门槛。但它们的价值锚定在编排层。随着模型越来越擅长工具调用、上下文管理和多步推理,纯编排层的壁垒会持续下降,除非它能上移到业务对象层和结果资产层——而目前这两层都是空的。
第三类:业务就绪。 目前最接近 Agentic Asset Loop 完整形态的是 Harvey。估值 110 亿美元,超过 10 万法律专业人士在用。它围绕法律任务建了完整的任务流,有 Vault 做文档知识库,有 Agent Builder 供客户创建定制化的 workflows 和 agents(公开资料显示已超过 25,000 个)。它有证据引用和源文档回溯,Agent 端到端执行法律工作,律师只做判断和决策。按年度企业订阅收费,外部报道显示其价格显著高于普通 SaaS 工具。
目前大多数产品停在了前两个阶段。第三个阶段的空白,就是 Agentic Asset Loop 指向的机会。
商业模式
“Token 成本加管理费”是很多人设想的 Agentic 商业模式:做一单赚一单,margin 靠效率差。问题是效率差会被追平,你今天比客户快 10 倍,明年工具进步了客户自己也能做到。
Agentic Asset Loop 指向一种不同的逻辑:卖的不是 Agent 的执行能力,而是资产的积累价值。
第一层收入是任务运行费。按任务量收费,覆盖 token 和工具成本。毛利不高,但它是启动飞轮的入口。
第二层收入是资产复用费。这里的资产复用分两层:一层是客户内部不断增厚的私有业务资产,提高单个客户的续费价值;另一层是可跨客户复用的方法资产、模板资产、领域本体、评估标准和工作流经验,这些会提高产品自身的交付效率和行业理解深度。
第三层收入是决策服务费。当资产积累到一定密度,产品可以从”帮你做研究”升级到”帮你做判断”。卖的是判断的稀缺性,这一层的毛利和护城河都远高于前两层。
这三层收入的逻辑同时也是壁垒的逻辑。 纯执行型 Agent 产品做不到第二层和第三层,因为没有资产层,每次都从零开始,没有东西可复用。
壁垒公式:领域知识密度 × 数据飞轮速度 × 工作流耦合深度 > 通用 Agent 能力提升速度。
这里有一个更深层的判断。传统 SaaS 的数据资产是结果数据,最终的报告、最终的合同、最终的分析结论。版本管理和审计日志很多时候只是为了应付安全审计要求,没人真的拿它当资产用。但对 Agent 来说,过程数据才是最珍贵的养料,每一次运行的判断逻辑、人工校准的记录、失败和跳过的步骤、置信度的变化历史。过程的调优和记录,才是垂直领域最有复利的环节。
一个产品的生命周期取决于它的核心价值锚定在哪一层。编排层的产品会被模型自身能力吞噬,工具层的产品会被下一代替代,只有锚在资产层的产品会越用越厚。
组织结构
这套理念真正改变的是组织里的判断分工。有了资产层,组织里就多了一类需要持续维护的东西,围绕它会长出新的角色和分工。
关键概念是判断密度,即一个岗位的工作中,需要人做不可替代判断的比例。搜资料、整理数据、写套路化报告、更新状态,这些工作的判断密度低,Agent 做得更快更好。定义目标、评审结论、处理例外、做最终决策,这些工作的判断密度高,只有人能做。前者会被 Agent 吸收进执行层,后者则会被放大,因为 Agent 把执行层交付了,人的每一个判断能撬动的产出量大幅增加。
因为系统持续积累资产,新的角色会自然生长出来。
- 资产管理员,因为有长期知识库需要维护,标记过期判断、合并重复、确保证据链完整。
- 领域审核员,因为资产入库前需要领域专家判断准确性,Harvey 团队里大量前大型律所律师做的就是这件事,把法律领域的专家经验翻译成 Agent 可执行的方法,同时审核 Agent 产出的质量。
- 智能体运维,因为 Agent 系统在生产环境中需要持续监控、成本管理和模型路由优化。
这些角色的共同特征是:它们的工作是校准系统,不是操作软件。
回到开头的三个现实:SaaS 解决的真问题不会消失,大多数公司仍在用 AI 强化传统产品范式,Coding 之外的领域还没有出现足够多被广泛认可的垂直 Agentic-first 产品。
Agentic Asset Loop 不是对这些问题的终极回答,而是一个设计假说:产品的核心价值不应该只锚定在 Agent 的单次执行能力上,而应该锚定在执行之后沉淀下来的业务资产上。这个假说是否成立,取决于它能不能在具体的垂直领域跑通完整循环:目标设定、任务执行、资产沉淀、人工校准、增量复用。
框架是纸上的,闭环要在泥里跑。