KV 缓存命中率
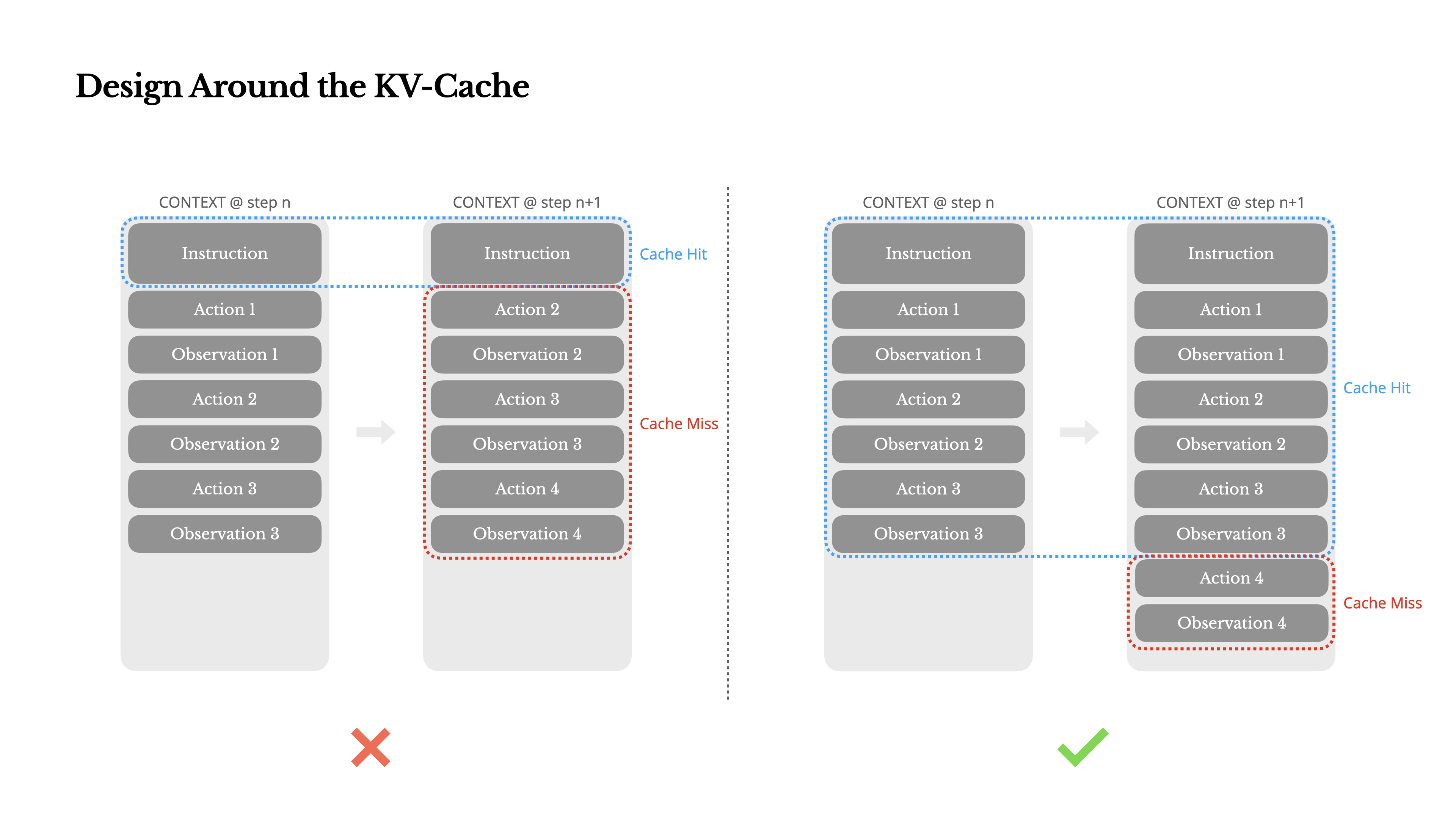
KV-cache 命中率是生存阶段 Agent 最重要的单一指标。直接影响延迟和成本。
随着每一步的推进,上下文不断增长,而输出(结构化函数调用)通常保持相对简短。这使得 Agent 相比于 Chatbot 的输入/输出比例高度倾斜。例如平均输入和输出的 token 比例是 100:1。
幸运的是,具有相同前缀的上下文可以利用 KV 缓存,这大大减少了首个 token 的生成时间和推理成本。这不是小幅度的节省:在 Claude 中,缓存的输入 token 成本为 0.3 美元/百万 token,而未缓存的成本为 3 美元/百万 token。
从上下文工程的角度,提高KV缓存命中率的关键实践有:
- 保持提示前缀稳定。 由于LLM的自回归特性,即使是单个标记的差异也会使该标记之后的缓存失效。一个常见的错误是在系统提示的开头包含时间戳——尤其是精确到秒的时间戳。
- 使你的上下文只追加。 避免修改之前的操作或观察,确保序列化是确定性的。(许多编程语言和库在序列化JSON对象时不保证键顺序的稳定性,这可能会悄无声息地破坏缓存。)
- 在需要时明确标记缓存 断点。某些模型提供商或推理框架不支持自动增量前缀缓存,而是需要在上下文中手动插入缓存断点。在分配这些断点时,要考虑潜在的缓存过期问题,并至少确保断点包含系统提示的结尾。
遮蔽,而非移除
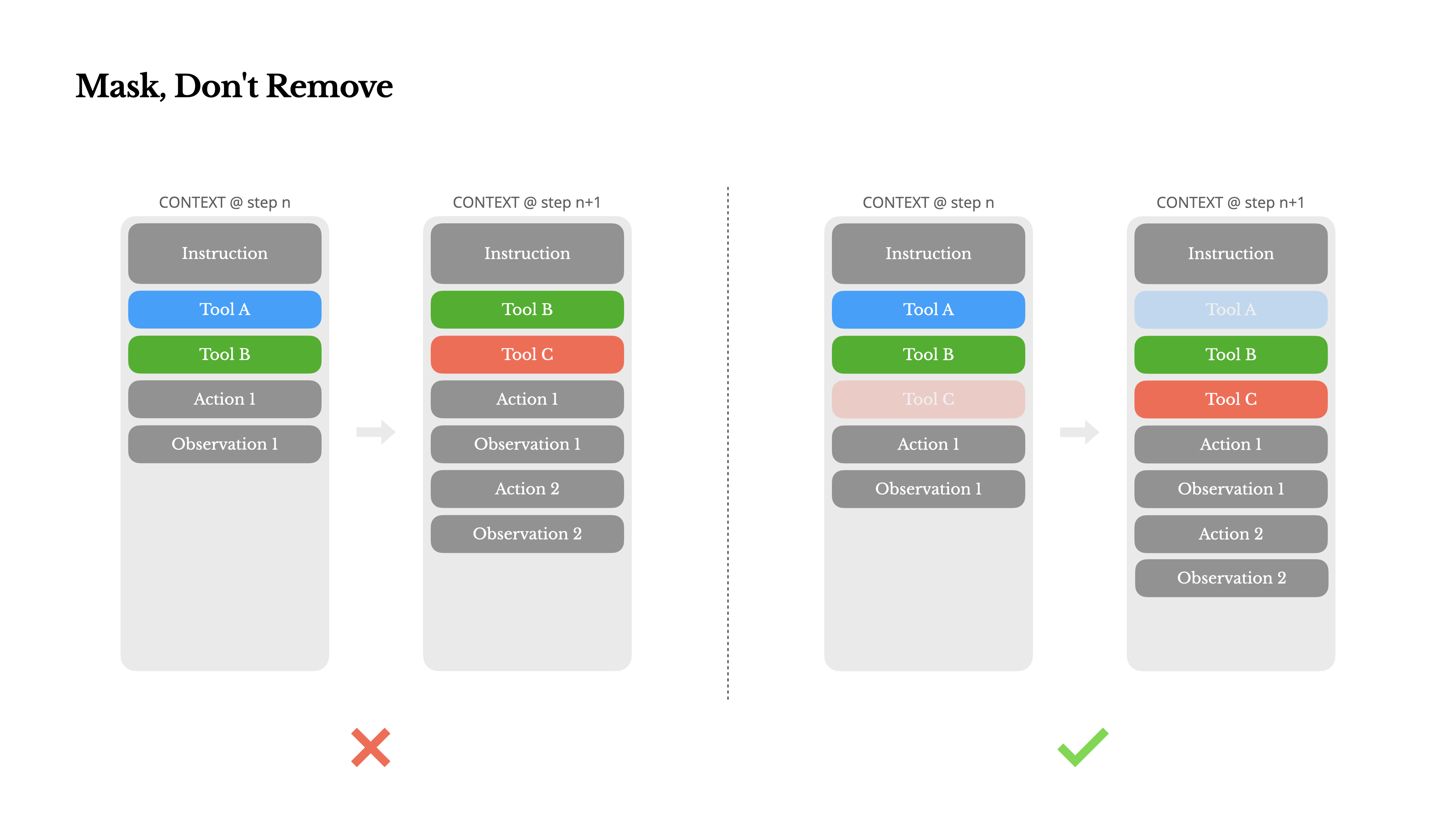
由于工具数量的爆炸式增长,模型更可能选择错误的行动或采取低效的路径。对此的反应是设计一个动态行动空间——使用类似 RAG 的方法按需加载工具。
但此处有一个明确的规则:除非绝对必要,避免在迭代过程中动态添加或移除工具。原因有二:
- 在大多数 LLM 中,工具定义在序列化后位于上下文的前部,因此任何更改都会使后续所有动作和观察的 KV 缓存失效。
- 当先前的动作和观察仍然引用当前上下文中不再定义的工具时,模型会感到困惑,这通常会导致模式违规或幻觉动作。
这个问题通过使用上下文感知的状态机来管理工具可用性。它不是移除工具,而是在解码过程中掩蔽 token,以基于当前上下文阻止(或强制)选择某些动作。
在实践中,大多数 LLM 支持某种形式的响应预填充,允许在不修改工具定义的情况下约束动作空间。函数调用通常有三种模式:
- 自动 - 模型可以选择调用或不调用函数。通过仅预填充回复前缀实现:
<|im_start|>assistant - 必须 - 模型必须调用函数,但选择不受约束。通过预填充到工具调用令牌实现:
<|im_start|>assistant<tool_call> - 指定 - 模型必须选择从特定子集中调用函数。通过预填充到函数名称的开头实现:
<|im_start|>assistant<tool_call>{"name": "browser_
使用文件系统作为上下文
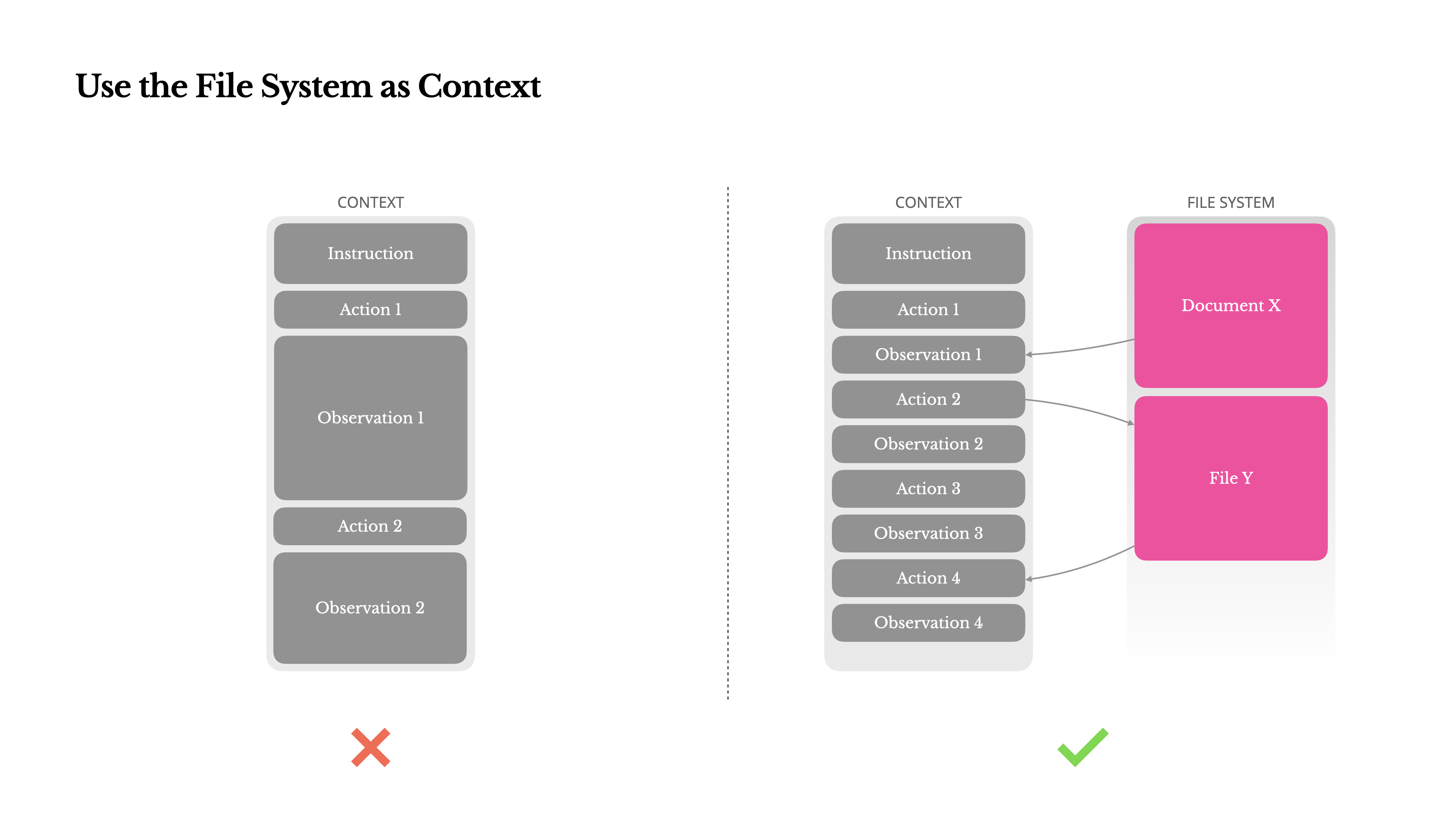
关于上下文窗口限制,常见的痛点有:
- 观察结果可能非常庞大:尤其是在 Agent 和网页或 pdf 等非结构化数据交互时,很容易超出上下文。
- 模型性能往往会下降:理论上的上下文窗口大小,并不等于实践。
- 长输入成本高昂:即便使用前缀缓存,仍需要为传输和预填充 token 付费。
为了解决这个问题,很多 Agent 系统实现了上下文截断或压缩策略。但过度激进的压缩不可避免的导致信息缺失。从逻辑角度看,任何不可逆的压缩都有风险。所以,Manus 将文件系统作为终极上下文:大小不受限制,天然持久化,Agent 可直接操作。模型按需写入和读取文件 —— 不仅将文件系统用作存储,还用做结构化的外部记忆。
同时,压缩策略始终是可恢复的。例如,只保留 URL,即可移除网页内容;保留文件路径,即可省略文档内容。
通过复述操控注意力
在处理复杂任务时,倾向于创建一个todo.md文件,并在任务进行过程中逐步更新它,勾选已完成的项目。
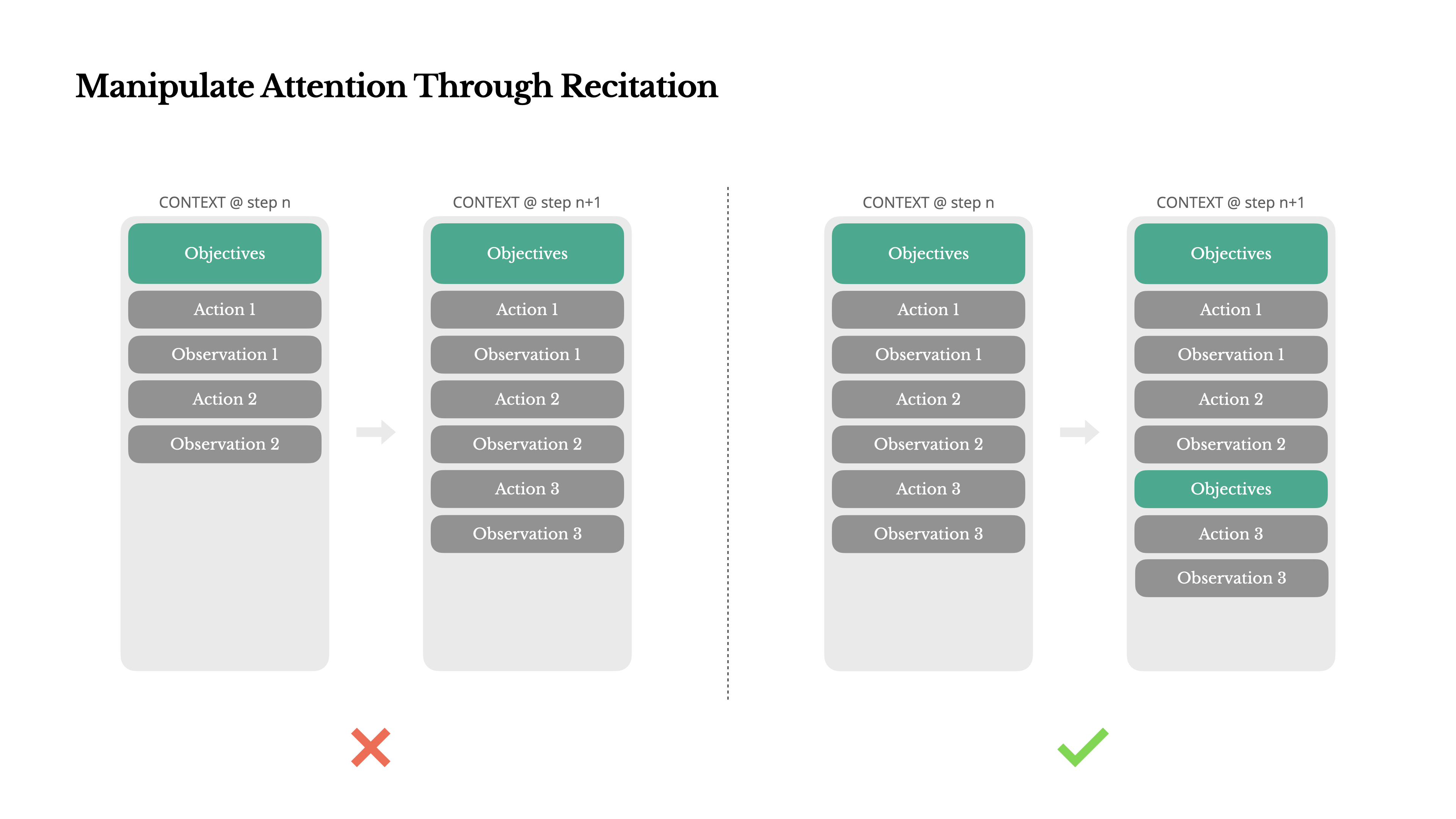
通过不断重写待办事项列表,Manus 将其目标复述到上下文的末尾。这将任务的全局计划圈入模型的近期注意力范围内,避免了“丢失在中间”的问题。它使用自然语言来使自己的注意力偏向任务目标——而不需要特殊的架构变更。
保留错误信息
在多步骤任务中,失败不是例外;它是循环的一部分。
一个常见的冲动是隐藏这些错误:清理痕迹,重试操作,或重置模型的状态并将其留给神奇的“temp”。但代价是:擦除失败会移除证据。没有证据,模型就无法适应。

改善 Agent 行为最有效的方法:将错误的尝试保留在上下文中。当模型看到一个失败的行动——以及由此产生的观察结果或堆栈跟踪——它会隐式地更新其内部信念。这会改变其先验,降低重复相同错误的可能性。
事实上,我们认为错误恢复是真正 Agent 行为的最明显指标之一。
不要被上样本示例所困
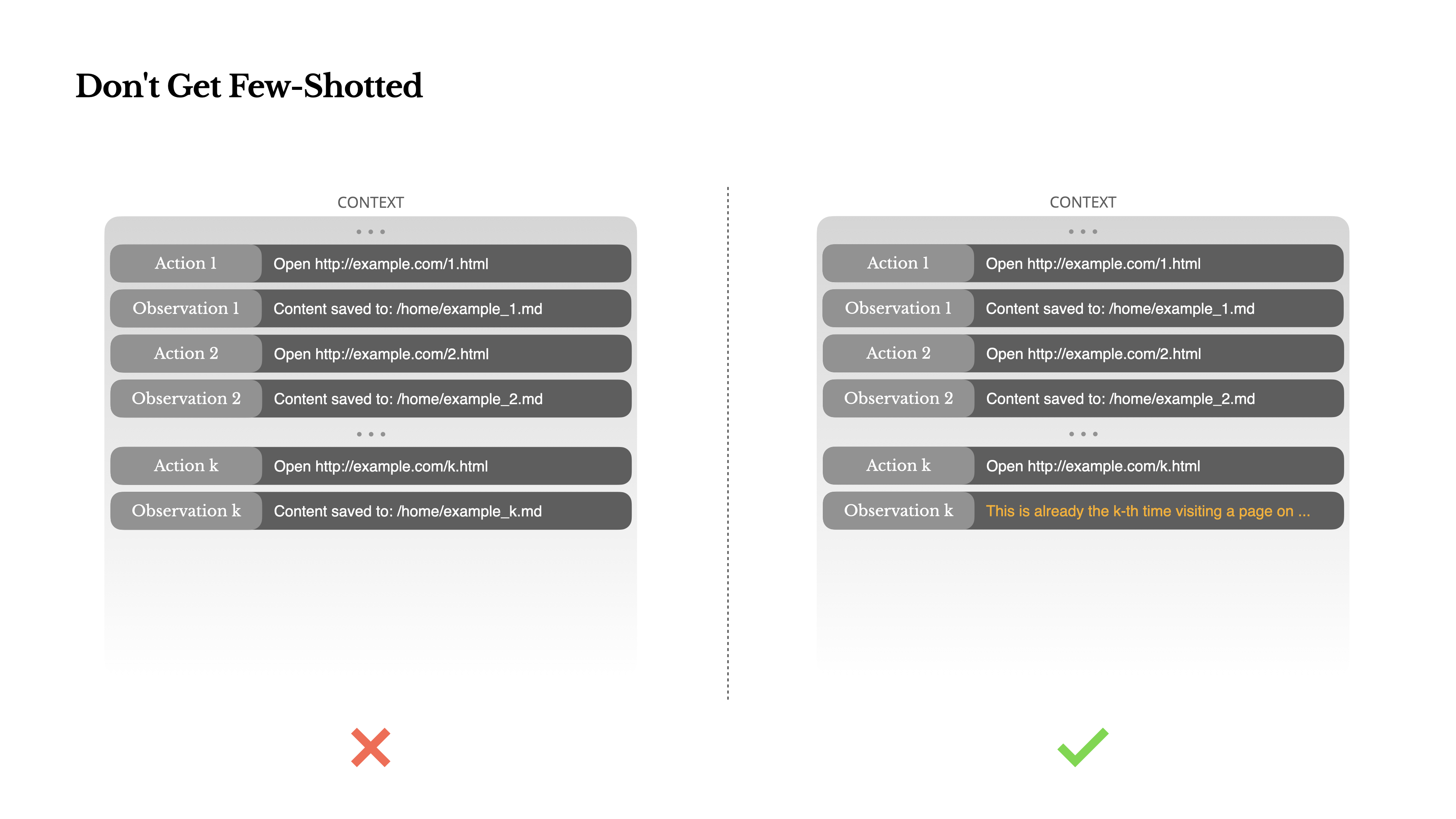
在 Agent 系统中,few-shot 可能会以微妙的方式适得其反。
LLM 会模仿上下文中的行为模式。如果上下文中充满了类似的过去行动-观察时,模型将倾向于遵循该模式,即使这不是最优解。
解决方法是增加多样性,在行动和观察中引入少量的结构化变化——不同的序列化模版、替代性措辞、顺序或格式上的微小噪音。这种受控的随机性有助于打破模式并调整模型的注意力。